Einführung
Das Problem, Häufigkeitsverteilungen miteinander zu vergleichen...
Empirisch erhobene Daten können anhand von Häufigkeitsverteilungen tabellarisch zusammengefasst oder grafisch dargestellt werden (s. Abbildung). Oft will man Datensätze vergleichen. Es interessiert beispielsweise, ob Studentinnen für die Bearbeitung eines Lernschritts durchschnittlich mehr Zeit aufwenden als Studenten. Mit tabellarisch oder grafisch dargestellten Häufigkeitsverteilungen sind eindeutige Aussagen zu derartigen Fragen nur schwer oder kaum möglich.
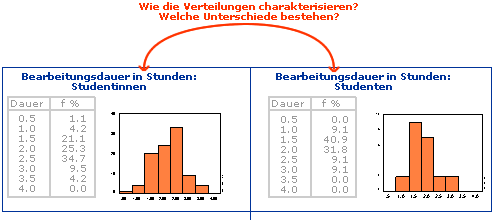
Wie können Häufigkeitsverteilungen beschrieben werden?
Die Form der Verteilung kann beschrieben werden, indem beispielsweise auf die Symmetrie oder die Steilheit eingegangen wird. Ein Datensatz kann damit aber nur ungenau charakterisiert werden. Es stellt sich deshalb die Frage:
- Wie kann ein Datensatz auf das Wesentliche reduziert werden?
- Wie können solche Häufigkeitsverteilungen möglichst knapp charakterisiert werden?
- Wie können Datensätze verdichtet werden, dass Vergleiche zwischen verschiedenen Datensätzen möglich sind?
Die Lösung: Die Einführung von Kennwerten zur Beschreibung univariater Verteilungen.
Das Bestreben der Deskriptiven Statistik, Beobachtungsdaten knapp zu charakterisieren, hat zur Entwicklung einer Anzahl von Kennwerten geführt. Diese sollen die Daten möglichst gut repräsentieren und zur Beschreibung der Verteilung verwendet werden können. Dabei werden viele Einzelinformationen zu wenigen, aber aussagekräftigen Grössen verdichtet.
Nachteil von Kennwerten
Da durch die Verdichtung der Daten zu Kennwerten notwendigerweise Informationen verloren gehen, muss dennoch häufig auf den Datensatz oder die Häufigkeitsverteilung zurückgegriffen werden. Der Nachteil von Informationsverlust wird jedoch oft in Kauf genommen, weil Kennwerte leichter vergleichbar und mitteilbar sind als Häufigkeitsverteilungen.
Zwei Gruppen von Kennwerten zur Beschreibung von Häufigkeitsverteilungen
Häufigkeitsverteilungen können auf zwei verschiedene Arten charakterisiert werden:
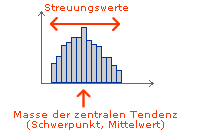
Masse der zentralen Tendenz (Mittelwerte)
Auf unterschiedliche Weise kann der „Schwerpunkt“ einer Verteilung beschrieben werden. Dies ermitteln die sogenannten Masse zur zentralen Tendenz, auch Lagemasse genannt.
Streuungswerte
Häufig interessiert auch die Frage, wie dicht die einzelnen Daten beieinander liegen, oder wie stark sie streuen. Man spricht von einer starken Streuung, wenn die Daten weit auseinander liegen.